Revealing the structure of language model capabilities
Abstract
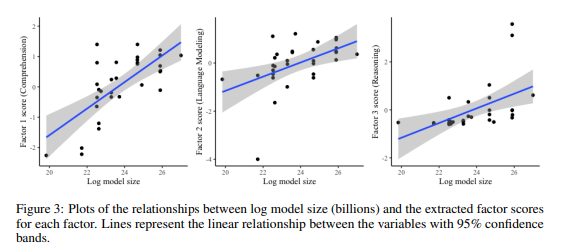
Building a theoretical understanding of the capabilities of large language models (LLMs) is vital for our ability to predict and explain the behavior of these systems. Here, we investigate the structure of LLM capabilities by extracting latent capabilities from patterns of individual differences across a varied population of LLMs. Using a combination of Bayesian and frequentist factor analysis, we analyzed data from 29 different LLMs across 27 cognitive tasks. We found evidence that LLM capabilities are not monolithic. Instead, they are better explained by three well-delineated factors that represent reasoning, comprehension and core language modeling. Moreover, we found that these three factors can explain a high proportion of the variance in model performance. These results reveal a consistent structure in the capabilities of different LLMs and demonstrate the multifaceted nature of these capabilities. We also found that the three abilities show different relationships to model properties such as model size and instruction tuning. These patterns help refine our understanding of scaling laws and indicate that changes to a model that improve one ability might simultaneously impair others. Based on these findings, we suggest that benchmarks could be streamlined by focusing on tasks that tap into each broad model ability. slug: revealing-the-structure-of-language-model-capabilities
Han Hao
Assistant Professor
Working memory, attention, intelligence, psychometrics, and R programming.